
Professionelle
Data Science -Werkzeuge
Bringen Sie Ihre Firma auf das nächste Level

Unsere Dienstleistungen
Holistische Blick auf die Datenanalyse
Induktive | Deskriptive Statistik
Eine deskriptive Statistik beschreibt einen Datensatz und deren Eigenschaften. Das Ziel der deskriptiven (beschreibenden) Statistik ist es meist, eine Stichprobe von empirischen Daten zu beschreiben. Die deskriptive Statistik verwendet Kennzahlen für die Häufigkeiten der Werte, die Lage der Daten (wie den Mittelwert), deren Verteilungsbreite (z.B. Standardabweichung) und Symmetrie dieser Verteilung, Tabellen oder Grafiken, oder mehrere davon. Aufgrund der deskriptiven Beschreibung einer Stichprobe lässt sich beurteilen, ob die Stichprobe repräsentativ sein könnte für eine größere Grundgesamtheit, z.B. wenn sie dieselben Eigenschaften besitzt.






Explorative Statistik
In der explorativen Datenanalyse gehen wir nun einen Schritt weiter und versuchen, mit Hilfe von geeigneten Darstellungen und Berechnungen die Daten nach Mustern oder Zusammenhängen zu untersuchen. Daher auch der Begriff „explorativ“ – wir forschen (explorieren) in den Daten nach interessanten Informationen, die man bei der einfachen Betrachtung in der deskriptiven Analyse nicht auf den ersten Blick sehen kann. Wir werden zum Auffinden von Mustern und Zusammenhängen sowohl bestimmte Arten von Grafiken verwenden als auch grundlegende Arten von Berechnungen: Korrelation und Regression.



Klassifikation
Klassifikation ist das Einordnen von Objekten in vorgegebene Klassen. Die Frage lautet: In welche Klasse passt ein gegebenes Objekt aufgrund seiner individuellen Merkmalskombination am besten? In der Statistik spricht man meist von Diskriminanz-analyse, in der KI (od. »schwache« künstliche Intelligenz) von Mustererkennung (engl.: pattern recognition).
-
Entscheidungsbäume (ID3, C4.5, C5.0, CART, CHAID, QUEST, SLIQ, SPRINT usw.)
-
Vorteile: Entscheidungsbäume können sehr einfach in leicht interpretierbare Wenn- Dann-Regeln konvertiert werden, indem man alle Pfade von der Wurzel bis zu den Blattknoten durchläuft und auflistet. Aufgrund dieser Eigenschaft werden sie auch im Anschluss an Clusteringverfahren eingesetzt, um eine gewonnene Partitionierung besser verstehbar zu machen. Dadurch, dass die Attribute, die am meisten zur Klassifikation beitragen, in die Nähe der Wurzel des Entscheidungsbaums gesetzt werden, können Entscheidungsbaumverfahren auch zur Priorisierung von Attributen dienen.
-
Nachteile: Bei den meisten Verfahren müssen die Trainingsdaten komplett im Hauptspeicher gehalten werden.
-
-
Bayes-Klassifikation
-
Vorteile: Naive Bayes-Klassifikation erzielt bei Anwendung auf großen Datenmengen eine hohe Genauigkeit und eine vergleichbare Geschwindigkeit wie Entscheidungsbaum-verfahren und neuronale Netze.
-
Nachteile: Wenn die Annahmen über Verteilungen und die Unabhängigkeit der Attribute ungerechtfertigt sind, werden die Ergebnisse ungenau.
-
-
k-nächste-Nachbar-Verfahren
-
Vorteile: Das Verfahren ist grundsätzlich sowohl für metrische als auch für kategoriale Merkmale anwendbar, das Ähnlichkeits- bzw. Distanzmaß muss nur entsprechend sinnvoll definiert werden. Die Lernphase entfällt praktisch: Alle Trainingsdaten werden nur zwischengespeichert und erst ausgewertet, wenn neue Objekte zu klassifizieren sind (»lazy learning«).
-
Nachteile: Die Klassifikationsphase ist sehr aufwändig. Für jeden einzelnen Klassifikationsvorgang muss die gesamte Trainingsmenge zur Verfügung stehen und nach ähnlichen Objekten durchgearbeitet werden. Die Anzahl der zu berücksichtigenden Nachbarn k muss von außen festlegt werden. Für größere Werte von k nimmt der Aufwand noch zu.
-

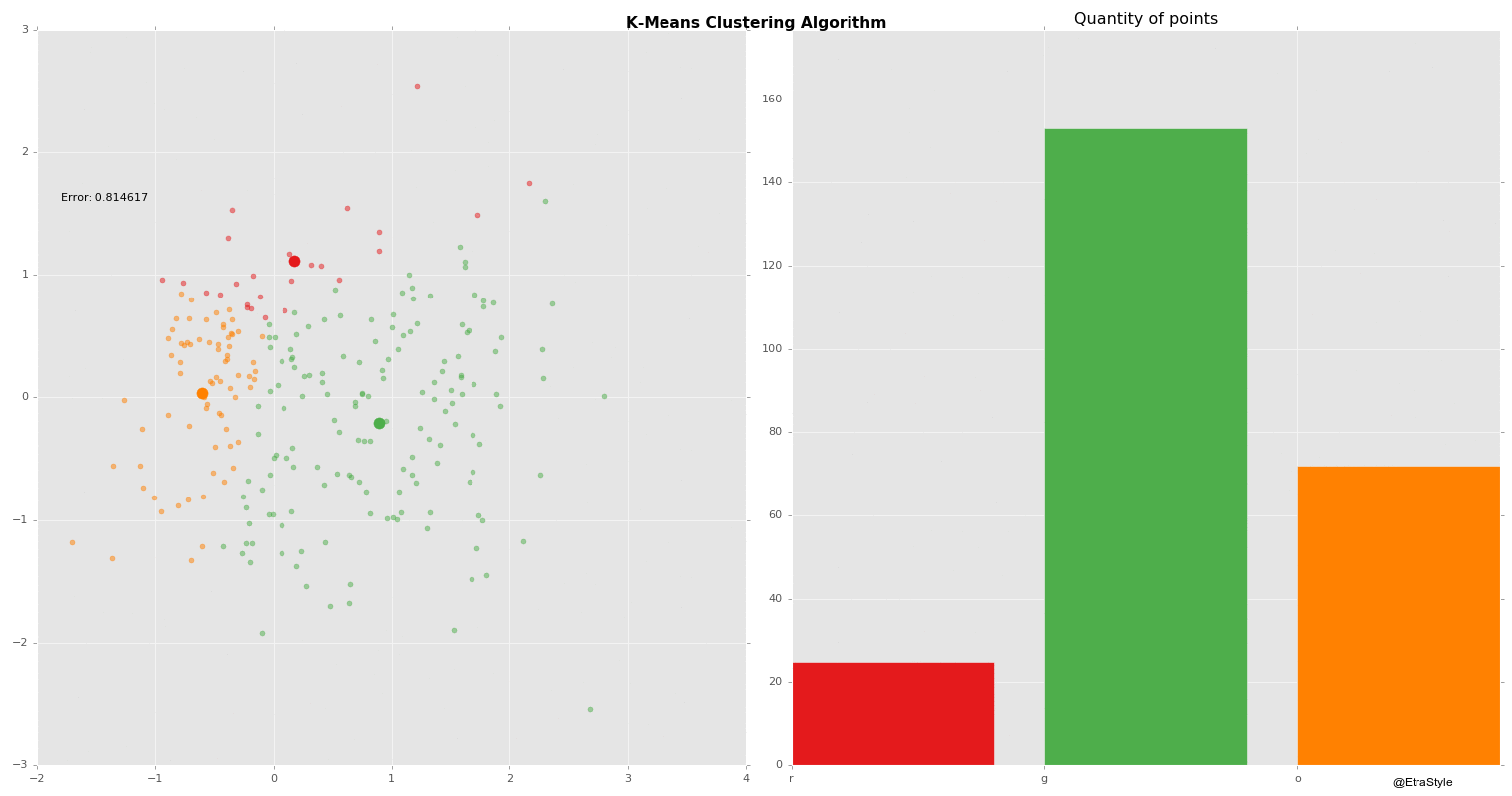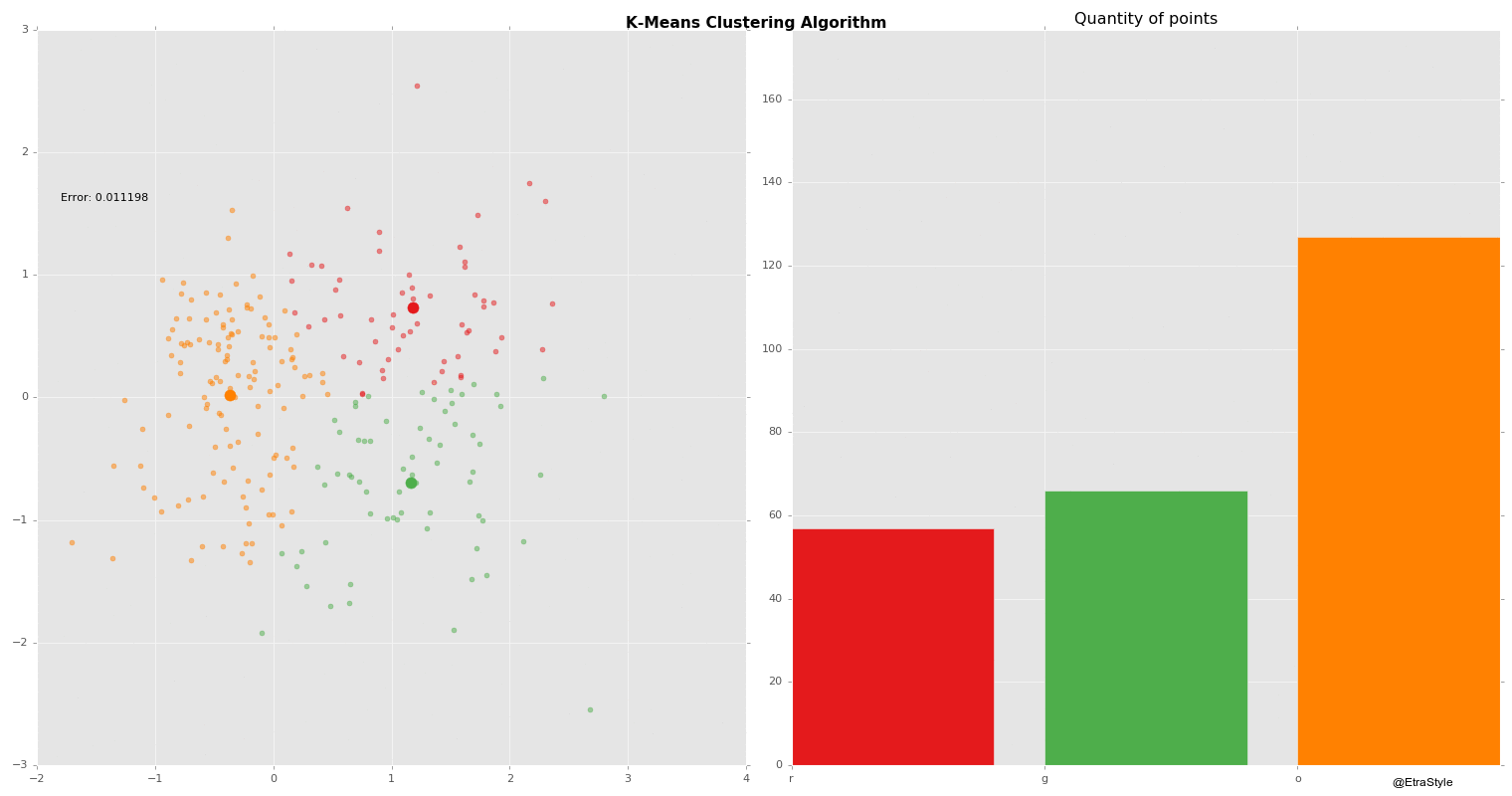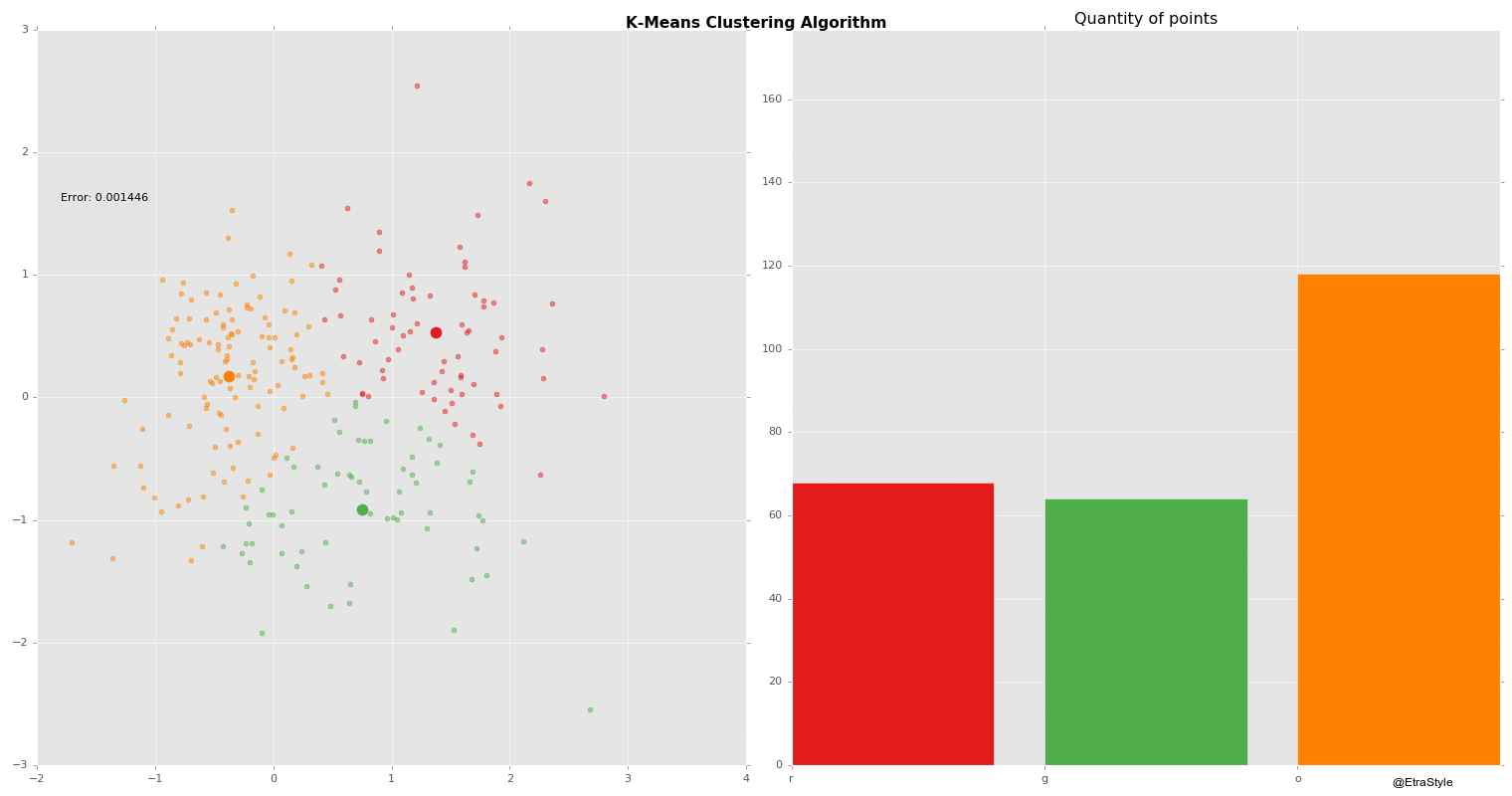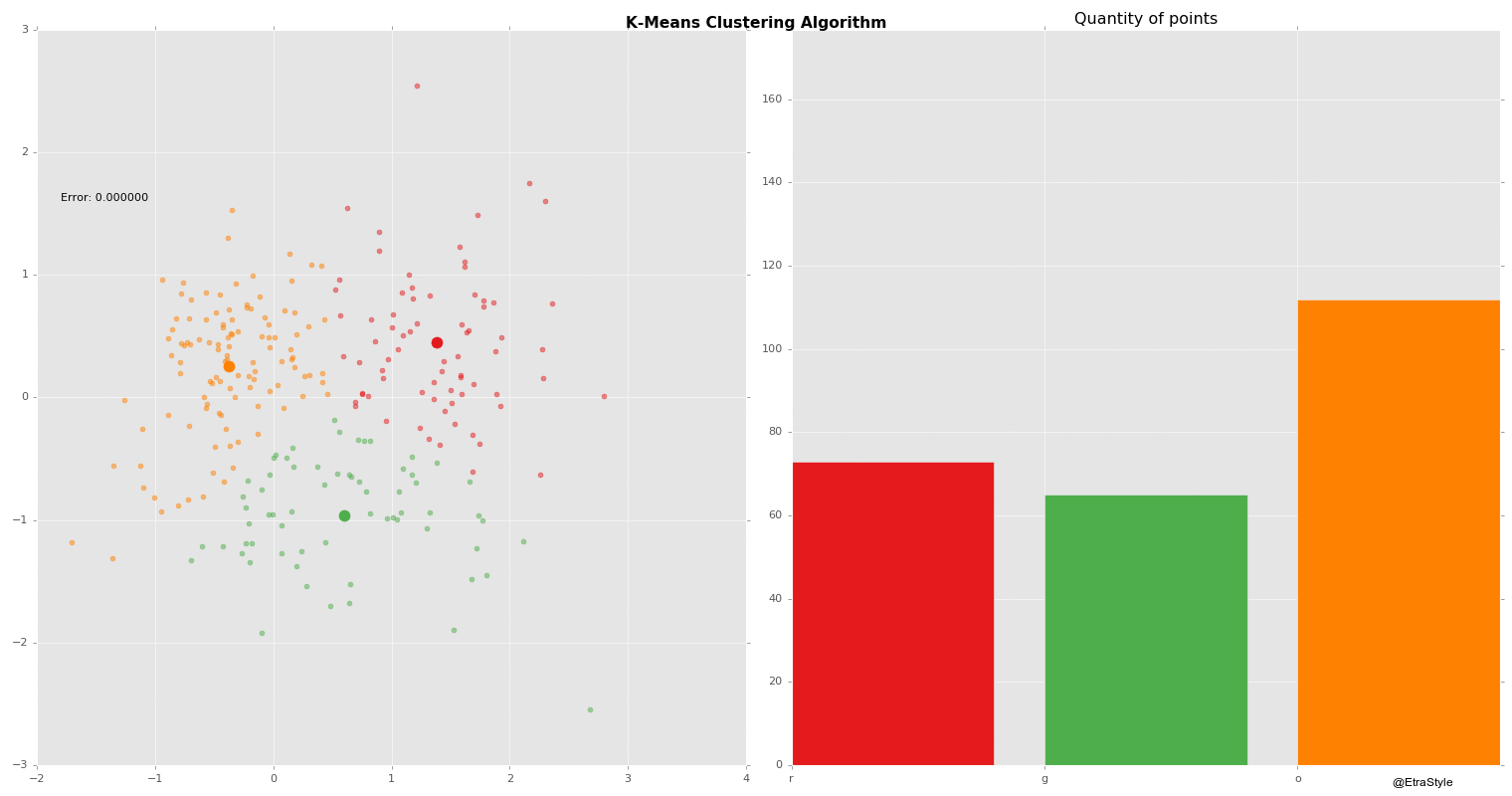

Clustering | Mustererkennung
Beim Clustering werden Objekte anhand ihrer Merkmale zu Gruppen, sogenannten Clustern, zusammengestellt. Die Gruppierung soll dabei so erfolgen, dass die Objekte innerhalb eines Clusters sich möglichst ähnlich, die Cluster untereinander sich aber möglichst unähnlich sind.
-
Hierarchische Verfahren (AGNES, BIRCH, CURE, Chameleon DIANA, ROCK, usw.)
-
Vorteile: Die Anzahl der Cluster muss nicht vorgegeben werden. Hierarchische Verfahren eignen sich besonders, wenn man an den Verbindungen zwischen den Clustern interessiert ist. Implementierungen sind weit verbreitet.
-
Nachteile: Aufgrund der nötigen paarweisen Distanzbildung für alle Objekte sind hierarchische Verfahren schlecht skalierbar und in der Praxis auf wenige tausend Elemente beschränkt. Einmal getroffene Zusammenfassungen von Clustern können nicht wieder rückgängig gemacht werden. Das Clustering selbst orientiert sich an lokalen Kriterien. Gute lokale Fusionsentscheidungen müssen aber nicht zu global guten Partitionierungen führen. Hierarchische Verfahren haben Probleme mit Ausreißern und nicht-konvexen Clustern.
-



-
Partitionierende Verfahren (k-means, PAM bzw. k-medoids, k-prototypes, CLARA, CLARANS, usw.)
-
Vorteile: k-means ist für kleine Clusteranzahlen recht effizient (der Rechenaufwand wächst linear mit den Anzahlen der Objekte, Cluster und Attribute). Implementierungen sind weit verbreitet.
-
Nachteile: Die Clusteranzahl muss vorgegeben werden. Die Ergebnisse werden stark beeinflusst von der Wahl der Startgruppierung und dem Umordnungsverfahren. Oft werden nur lokale Optima der Gütefunktion ermittelt. K-means und k-medoids sind nicht für große Datenmengen und nicht bei komplexen Clusterformen geeignet.
-
-
Dichtebasierte Verfahren (DBSCAN, OPTICS, DENCLUE, CLIQUE, WaveCluster, MAFIA usw.)
-
Vorteile: Dichtebasierte Verfahren können Cluster in beliebiger Form erkennen (im Gegensatz z. B. zu Verfahren, die mit metrischen Distanzmaßen arbeiten und nur konvexe Cluster bilden). Sie sind auch für große Datenmengen geeignet.
-
Nachteile: Die Qualität der gefundenen Partitionierung hängt stark von der Wahl der Inputparameter (Umgebungsgröße, Mindestzahl von Objekten) ab.
-




Neuronale Netze (deep learning)
Neuronale Netze bestehen aus mehreren Knoten (Neuronen) die miteinander verbunden sind und sich gegenseitig aktivieren. In ihrer gebräuchlisten Form als fully-connected, feed- forward, multilayer perceptrons sind die Neuronen in mehreren Schichten angeordnet (Eingabeschicht, eine oder mehrere verborgene Schichten, Ausgabeschicht) und jedes Neuron ist mit allen Neuronen der nachfolgenden Schicht verbunden. Die Verbindungen zwischen den Neuronen sind mit anfangs zufälligen Gewichten belegt.


-
Vorteile: Neuronale Netze können sehr gut mit Ausreißern umgehen und solchen Objekten, deren Merkmalskombination nicht in der Trainingsmenge vorgekommen ist.
-
Nachteile: Die erlernten Gewichte sind kaum zu interpretieren. Somit lässt sich das Klassifikationsergebnis nicht erklären. Inzwischen gibt es allerdings einige Verfahren, die versuchen, aus den Gewichten Regeln abzuleiten. Die Trainingsphase dauert sehr lange, besonders wenn die Anzahl der Attribute groß ist. In diesem Fall kann es auch sein, dass gar keine gute Lösung gefunden wird. Neuronale Netze erfordern besondere Sorgfalt bei der Datenvorbereitung, z. B. bei der Normalisierung der Daten. Kategoriale Daten müssen vorher sinnvoll in metrische Daten umgewandelt werden, was problematisch sein kann. Die Alternative, für jede mögliche Ausprägung ein eigenes Eingabeneuron einzusetzen, lässt die Trainingszeiten enorm ansteigen und verschlechtert die Qualität der Ergebnisse. Eine dem Problem angepasste Topologie des neuronalen Netzes (Anzahl der verborgenen Schichten, Anzahl der Neuronen jeder Schicht) ist nicht vorgegeben und muss anhand von Erfahrungswerten festgelegt werden.